
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- ssafy 7기
- SSAFYcial
- git
- ssafy 7기 교수님
- DenseNet
- bfs
- 알고리즘
- SWEA
- 유니온 파인드
- 프로그래머스
- 백준7576 bfs
- 삼성 청년 SW 아카데미
- dfs
- 코딩 교육
- pytorch
- ssafy 7기 합격
- 전이학습
- DP
- 웹 표준 사이트 만들기
- 싸피 7기 입학식
- 프로그래머스 고득점 kit
- SSAFY
- SSAFY 8기
- Learning
- 백준
- 코딩교육
- 이코테
- React
- 삼성청년sw아카데미
- SSAFY 입학식
- Today
- Total
개미의 개열시미 프로그래밍
[2~3주차] DenseNet <이론 정리편> 본문
원래는 전이학습을 정리하기 전에 먼저 올려야 순서가 맞지만 이미 Jupyer notebook으로 정리를 했기때문에 빨리 올려보려고 합니다.(복습도 할겸..!)
DenseNet정리도 마찬가지로 구글링, 유투브 그리고 논문과 학교에서 지원해준 FastCampus강의를 참고했습니다..
이번에 백마인턴쉽에서 맞게된 주제는 '유사 이미지 분류'이며 전이학습을 기반으로 하고 전에 설명했던 전이학습의 pre-trained model을 DenseNet을 씁니다.

DenseNet은 이전 layer의 feature map을 계속해서 다음 layer의 입력과 연결(Concatenation)하는 방식으로 ResNer과 매우 유사합니다. ResNet과 같이 Pre-Activation구조를 사용하는데(이 구조는 아래에서 더 자세히 설명) 이런 구조를 두어 Vanishing Gradiant 개선, Feature Propagation 강화, Feature Reuse, Parameter 수 절약을 할 수 있습니다..
- Vanishing Gradiant 개선 : Dense connectivity pattern을 가지면 모든 feature map들을 쌓아오기 때문에 layer 사이 사이 최대한 가치있는 정보가 지나다니게 만들 수 있습니다.. 초반 layer의 정보를 쌓아 뒤 쪽 layer까지 효율적으로 전달하여 error를 다시 역전파할때에도 효율적으로 전달하여 모델의 train이 쉬워집니다..
- parameter수 절약 : 기존 전통적인 네트워크보다 파라미터 수를 많이 줄일 수 있습니다. DenseNet의 layer들은 다른 네트워크들에 비해 굉장히 좁고 한 layer당 12개 정도의 filter를 가지며 이전의 feature map들을 계속 쌓아가면서 전체적인 내부의 정보들을 효율적으로 가져갑니다. 마지막 분류기에 네트워크 내부의 전체 feature map을 골고루 입력할 수 있게 만들어주며 동시에 전체 파라미터의 갯수를 줄여도 네트워크가 충분히 학습이 가능하도록 합니다.
DenseNet을 이해하기 위한 핵심용어 네가지 정리
- Growth Rate
- Bottleneck Layer
- Transition Layer
- Composite function
1. Growth Rate

각 layer의 feature map의 channel 개수를 뜻하며 위 그림에서 6개의 channel feature map이 입력으로 Dense block에 들어가 4번의 convolution block을 통해 output으로 (6+4+4+4+4=22)개의 channel을 가진 feature map을 출력하게 됩니다. ==> Channel of Input + k(growth rate) x (layer-1)
2. Bottleneck Layer

3x3 conv 전에 1x1 conv 연산을 통해 feature map의 channel 개수를 줄인 뒤 다시 입력 feature map의 channel 개수 만큼 생성하고 growth rate 만큼의 feature map을 생성하여 연산량을 줄입니다.

이름 그대로 >< 같은 모양이며 파라미터의 수는 줄이고 layer는 깊게 하는 특징이 있습니다.
1x1 Convolution을 하는 이유 <-- 강의 영상을 통해 쉽게 이해할 수 있습니다.
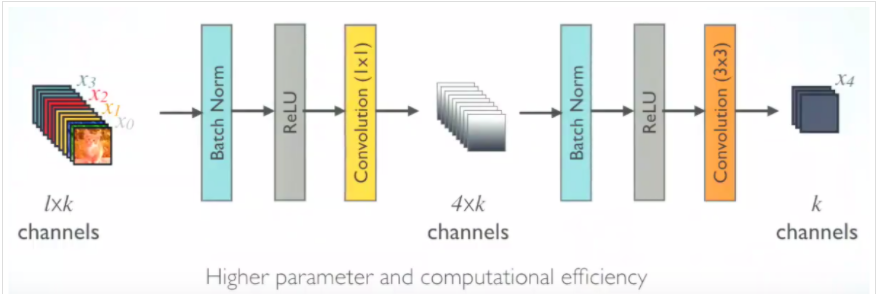

BN -> ReLU -> 3x3 conv 구조에서 BN -> ReLU -> 1x1 conv -> BN -> ReLU -> 3x3 conv의 bottleneck 구조를 적용하는 그림입니다.
3. Transition layer란?

위 그림은 총 3개의 Dense block으로 나뉘고 같은 블록 내의 layer들은 전부 같은 feature map size를 가지게 됩니다. 빨간 네모를 친 pooling과 convolution 부분을 transition layer라고 부릅니다.
feature map의 가로, 세로 사이즈를 줄여주고 feature map의 개수를 줄이는 역활을 담당하고 Dense block 사이에 구성되어 Batch Nomalization, ReLU, 1x1conv연산, 2x2 average pooling으로 구성되어 있습니다.
1x1conv연산을 통해 feature map의 개수를 줄여주며 결과적으로 Transition Layer를 통과하면 feature map의 개수(Channel)이 절반으로 줄어들고, 2x2 average pooling layer를 통해 feature map의 가로 세로 크기 또한 절반으로 줄어듭니다.
참고로 처음에 사용되는 convolution연산은 input이미지의 사이즈를 dense block에 맞게 조절하기 위한 용도로 사용되었습니다. 따라서 이미지의 사이즈에 따라 사용해도 되고 사용하지 않아도 됩니다.
4. Composite function
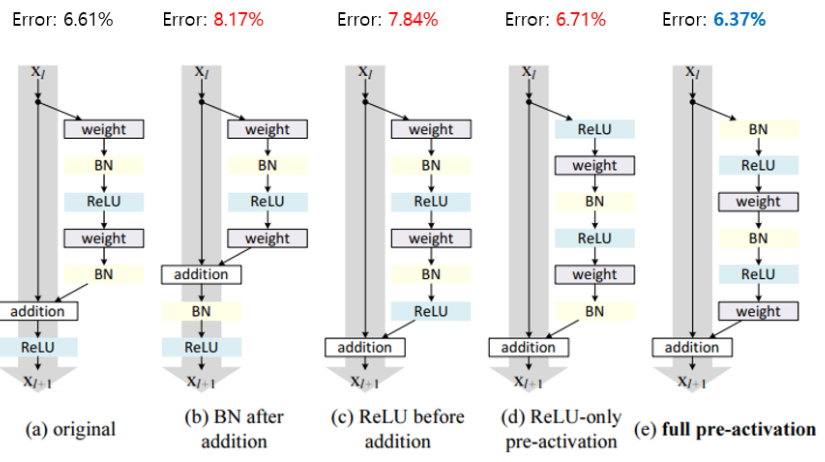
Pre-Act는 Pre-Activation의 약자로, Conv-BN-ReLU연산에서 Activation function인 ReLU를 Conv연산 앞에 배치한다고 해서 붙여진 이름입니다. ==> BatchNorm-ReLU-Conv의 순서
위 그림은 activation function의 위치에 따른 test error의 결과를 보여주고 있으며 기존에 Conv-BN-ReLU-Conv-BN을 거친 뒤 shortcut과 더해주고 마지막으로 ReLu를 하는 방식이었습니다. 총 44가지 변형 구조로 test error를 측정한 결과 full pre-activation 구조 일때 가장 test error가 낮은 것을 확인할 수 있었습니다.
이제 논문에서 나온 그 외에 개념을 정리하겠습니다.
- Compression
모델을 더 컴팩트하게 만들기 위해서, transition layer에서 feature map의 수를 줄여줍니다.
만약 Dense block을 모두 통과한 feature map의 갯수가 m개라면 이 transition layer를 거치면 ym개가 되며 y는 우리가 지정해주는 hyper parameter이며 0보다는 크고 1보다는 작거나 같은 값을 가집니다. 만약 1이라면 feature map의 갯수는 변하지 않고 그대로 계속 쌓여나간다고 할 수 있습니다.
- DenseNet Structure

위 그림에서 첫 convolution을 통과하며 16개의 채널이 나옵니다. feature map size를 고정시키기 위해 zero padding을 시행하며 dense block을 수행하고 나면 transition layer를 거치고 feature map의 size가 작아지면서 다음 dense block을 수행합니다.
Densnet-121를 살펴보면 Dense Block마다 곱해지는 6, 12, 24, 16은 각 블록마다의 layer의 수로 총 121개의 layer를 가지기에 DenseNet-121이라고 표기합니다.
- GAP(Global Average Pooling)

- GAP란 Max Pooling 보다 더 급격하게 feature의 수를 줄이며 목적은 feature를 1차원 벡터로 만들기 위함입니다.
- 마지막 Classification layer에서 대부분의 네트워크 구조의 마지막 layer에는 fully-connected network를 넣어주지만 여기서는 GAP(Global Average Pooling)을 사용합니다. 이유는 네트워크 구조가 점차 발전하면서 굳이 파라미터의 수가 매우 많이 증가하는 FC를 넣어주지 않기 때문으로 보입니다.
- 위 그림을 보면 같은 채널(같은 색)의 feature들을 모두 평균을 낸 다음에 채널의 갯수(색의 갯수) 만큼의 원소를 가지는 벡터를 만듭니다.
- (height, width, channel) -> (channel,) 형태로 간단히 변환
- 어떤 크기의 feature라도 같은 채널의 값들을 하나의 평균 값으로 대체하기 때문에 벡터가 됩니다. 따라서 어떤 사이즈의 입력이 들어와도 상관이 없습니다. 또한 파라미터의 갯수가 FC layer 만큼 폭발적으로 증가하지 않아서 overfitting 측면에서도 유리하며 이런 이유로 FC Layer 대신 사용가능합니다.
많은 분들의 자료를 보았고 이해되는 부분과 중요하다 싶은 부분으로 정리를 해보았습니다!
또 다음은 DenseNet의 코드를 직접 보면서 이해를 하는 글을 올리도록 하겠습니담
<참고자료>
jayhey.github.io/deep%20learning/2017/10/15/DenseNet_2/
hoya012.github.io/blog/DenseNet-Tutorial-1/
arxiv.org/pdf/1608.06993.pdf
gaussian37.github.io/dl-concept-global_average_pooling/
gaussian37.github.io/dl-concept-densenet/
'인턴쉽 > 동계백마인턴쉽(2021)' 카테고리의 다른 글
| [5주차] '유사 이미지 분류' Trainer코드 제작 (0) | 2021.02.08 |
|---|---|
| [4주차] 전이학습(Transfer Learning) <실습 정리편> (0) | 2021.02.08 |
| [4주차] 전이학습(Transfer Learning) <이론 정리편> (0) | 2021.02.08 |
| [1주차] 환경세팅하기 (Anaconda + PyTorch) (1) | 2021.02.08 |
| 동계백마인턴쉽(+플랜아이) 시작 (2) | 2021.02.08 |



