
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 코딩 교육
- 삼성청년sw아카데미
- pytorch
- SWEA
- 프로그래머스
- dfs
- 싸피 7기 입학식
- 프로그래머스 고득점 kit
- ssafy 7기 합격
- 백준7576 bfs
- 삼성 청년 SW 아카데미
- SSAFY 입학식
- React
- ssafy 7기 교수님
- DP
- git
- 알고리즘
- SSAFY
- SSAFYcial
- 웹 표준 사이트 만들기
- 코딩교육
- ssafy 7기
- SSAFY 8기
- Learning
- 유니온 파인드
- bfs
- 전이학습
- 이코테
- DenseNet
- 백준
- Today
- Total
개미의 개열시미 프로그래밍
[6~7주차] '유사 이미지 분류기' 구현완성 본문
이번에 6,7주차를 한번에 작성하게 된 건 2주동안 유사이미지분류기를 고도화하거나 리팩토링하는데 초점을 두어서 나눌 필요가 없다고 생각했지만 사실 시간이 없기도 했습니다...

원래 기존의 아키텍쳐에서 많이 변경된 모습인데 처음 하는 협업이라 그런지 인턴분과 의사소통을 하는 부분에서 많은 미스가 있었습니다.
'혼자 이렇게 구성하면 더 좋지 않을까' 라는 생각에 마음대로 수정하기도 했고 yaml파일과 trainer.py 코드도 두개로 나뉘는 것부터 소통이 잘 안된 것을 알 수있었습니다. (tester.py도 두개가 되버려서 통합하는데는 성공..)
개발자들은 원래 코드의 아키텍쳐를 서로 공유하고 설계본을 많이 안건드리는 선에서 작업을 한다고 합니다!
만약 디렉토리나 코드 변수에 대해 변경을 한다면 같이 하는 작업자에게 반드시! 알려야합니다.
물론 소통부분에서 문제가 많았지만 왜 Slack, Git, Notion을 쓰는지에 대해 뼈저리게 경험을 할 수 있어 좋았습니다.
갑자기 이야기가 샛지만 다시 본론으로 돌아와 6~7주차에 했던 이 전부터 해오던 '유사이미지분류기'에 대해 정리를 하려고 합니다.
위의 아키텍쳐 이미지에서 내가 작업을 했던 부분은 아래와 같고 순서대로 정리를 하겠습니다.
- environments_byJo.yaml : 데이터 전처리 및 모델학습에 필요한 값들이 저장된 파일
- data_processing_byJo.py : 데이터를 로드하고 전처리해주는 코드
- densenet_trainer_byJo.py : 로드된 데이터를 학습 및 평가 하는 코드
DATALOAD
원하는 데이터셋(사용자가 분류하고 싶은 데이터셋)을 로드하는 부분입니다. 따로 모듈화를 한 것은 한 파일안에 모든 코드가 들어가는 것이 보기 않좋아 보였습니다.
[environment_byJo.yaml]
먼저 데이터 전처리 및 모델학습에 필요한 값들이 저장된 파일은 아래와 같습니다.
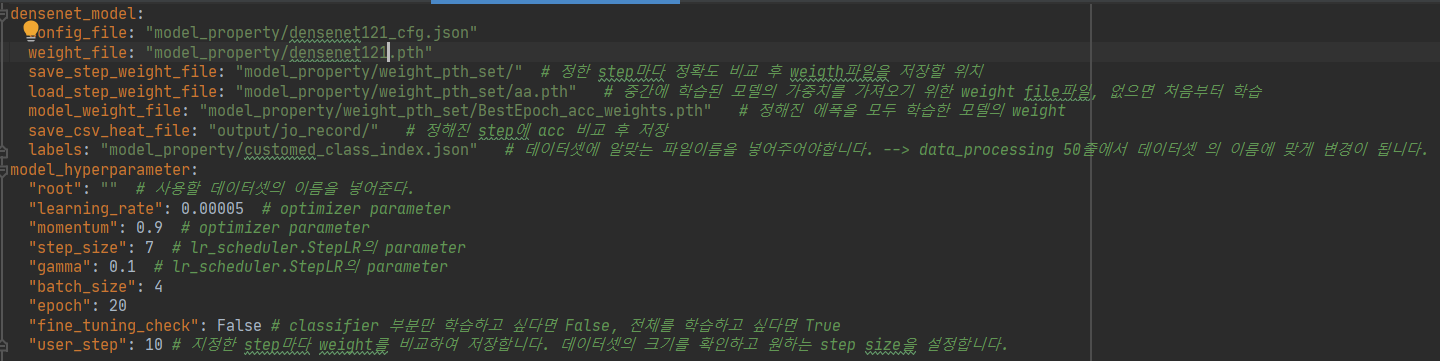
- yaml파일 안에서도 크게 두 부분으로 나뉘는데 densenet_model은 모델이 학습하고 난 뒤에 담길 가중치 파일들과 평가도중에 만든 csv, heatmap들을 저장하는 경로들이 담겨있습니다.
- model_hyperparameter는 변수명만 봐도 알 수 있듯 모델이 학습에 필요한 hyper parameter들을 저장되어 있습니다.
yaml파일로부터 경로와 hyper parameter를 받아서 데이터로드 및 전처리와 모델이 학습 및 평가 마지막으로 저장까지 되도록 도와주고 이 파일로 인해 사용자가 경로와 parameter를 쉽게 변경이 가능하도록 구현하였습니다.
추가적으로 config_file의 경로를 불러와 아래와 같이 데이터 전처리에 대한 값들이 들어있습니다. 이부분도 언제든지 사용자가 쉽게 수정이 가능합니다.

[data_processing_byJo.py 코드정리]
이제 위의 yaml파일에서 config_file.json에 저장된 값들을 가져와서 데이터를 전처리해주는 코드가 담긴 파일입니다.
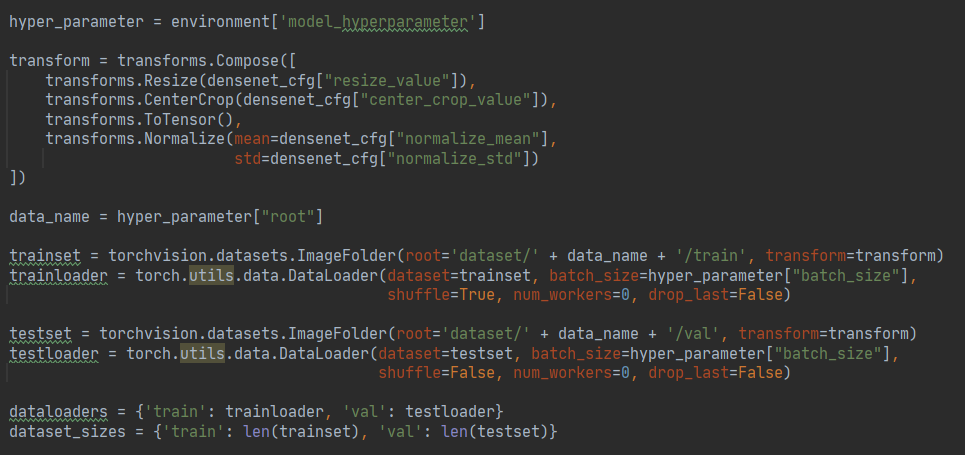
- transform.Copose를 통해서 cfg에 저장된 값들을 넣어주어 전처리를 합니다.
- torchvision의 ImageFolder를 적용한다면 이미지 폴더만 가지고 오게됩니다.
=> 이 ImageFolder에 대해 단순히 이미지만 가져오는 파일이구나 했지만 다른 인턴분이 이미지가 아닌 폴더를 가져오는 에러가 나서 같이 이유를 찾느라 고생을 했었습니다. 결국은 device를 지정해주는 문제였지만 mac환경에서 돌리는 경우 .Ds_Store라는 파일도 읽어버려서 오류가 날 수도 있었습니다. device지정을 잘해주지 않는다면 ImageFolder와 같이 편한 라이브러리도 말짱도루묵이라는 것을 알았습니다ㅠ
이렇듯 데이터를 로드하는 부분을 따로 둔 이유는 좀 더 편리함? 한 파일안에 너무 많은 내용이 들어가는 건 원치 않아서였습니다.(잘한건지는 모르겠다..)
DATA 학습 및 평가 (+모델생성, 시각화)
원하는 데이터셋를 로드했다면 모델정의, 손실함수 및 optimizer정의, 학습 및 평가, 시각화 순으로 흐름구성을 구현하였습니다.
[densenet_trainer_byJo.py 코드정리]

main부분의 주석을 보면 알 수 있듯이 동작은 데이터 다운로드를 통해 데이터들과 크기, 카테고리 수 등을 가져옵니다.
순서는 주석에도 써있지만 정리하자면,
- DataLoad
=> 전에 정리한 data_processing_byJo.py에서 데이터로드 및 전처리 된 데이터셋, 크기, 카테고리 갯수 등을 변수에 저장을 한다. - 고정 특징 추출기 생성(모델 정의)
=> 이 부분은 이전에 올렸던 전이학습 이론정리&실습정리편을 보면 알 수 있듯이 이전에 잘 학습된 모델의 가중치를 가져와서 새로 분류하고 싶은 데이터셋에 대해 마지막 classifier부분을 수정해서 새로운 모델을 만드는 부분이다. - train_model함수안에서 손실함수 및 Optimizer를 정의 한 뒤 생성한 모델을 가지고 학습 및 평가를 한다.
전이학습 이론정리&실습정리편
[DL] 전이학습(Transfer Learning) <이론 정리편>
먼저, 전이학습을 공부하려는 이유는 이번 백마인턴의 주제가 유사 이미지 분류 개발이며 코드의 큰 틀은 전이학습구조로 이루어지기에 과제를 진행하기 위해 꼼꼼히 이해하는 단계가 필요하
reliablecho-programming.tistory.com
[DL] 전이학습(Transfer Learning) <실습 정리편>
전이 학습(Transfer learning)은 직접 코드를 보면서 이해하는 것이 이해하는데 도움이 많이 되었습니다. 실습은 PyTorch.org 사이트에서 전이 학습에 대한 코드를 Colab, Jupyter notebook, GitHub으로 공유하고.
reliablecho-programming.tistory.com
[CustomModel 클래스 설명]
이제 위의 순서대로 설명을 진행하자면 고정 특징 추출기 모델을 생성(모델정의)해 주는 CustomModel 클래스로 이동을 하게 됩니다.
class CustomModel():
# TODO: 1. fixed feature extractor(고정된 특징 추출기) 모델 정의
'''
1-1. DenseModel.pth를 load하여 모델에 가중치를 넣습니다. -> pretrained model
1-2. pretrained model을 deepcopy한 model_conv의 fc layer를 초기화 합니다. ( 새로운 task에 맞는 class의 수)
'''
def __init__(self, property, hyper_parameter, class_length):
self.class_length = class_length
self.property = property
self.hyper_parameter = hyper_parameter
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
with open(self.property['config_file'], "r", encoding='UTF-8') as i:
densenet_cfg = json.load(i) # config_file : model의 hyper parameter
# Prepare Model
print("Loading DenseNet121 network.....")
self.model = DenseNet(
growth_rate=densenet_cfg["growth_rate"],
block_config=tuple(densenet_cfg["block_config"]),
num_init_features=densenet_cfg["num_init_features"]
)
self.model.load_state_dict(torch.load(property['weight_file'], map_location=self.device)) # 모델에게 가중치 부여
def make_model(self):
model_conv = deepcopy(self.model)
# 마지막 계층을 제외한 신경망의 모든 부분을 고정하여 backward() 중에 경사도가 계산되지 않도록함
if hyper_parameter["fine_tuning_check"] == True:
for param in model_conv.parameters():
param.requires_grad = False
num_ftr = model_conv.classifier.in_features
# 여기서 각 출력 샘플의 크기는 2로 설정합니다.
# 또는, nn.Linear(num_ftrs, len (class_names))로 일반화할 수 있습니다.
# output을 parameter로 받아주도록 해야한다!!
model_conv.classifier = nn.Linear(num_ftr, self.class_length)
# 만약에 이미 학습을 해놓은 가중치가 있다면 넣어주어야한다.
# os.path.isfile(property['classifier_weight_file'] + f"_{score}.pth"):
if os.path.isfile(self.property['load_step_weight_file']):
print("이미 학습된 weight를 모델에 씌웁니다.")
model_conv = model_conv.load_state_dict(self.property['load_weight_file'])
model_conv = model_conv.to(self.device)
return model_conv
- 먼저, __init__생성자를 통해서 yaml파일을 읽은 property와 hyper parameter값을 받아와 기존의 pre-trained된 모델을 생성합니다.
- make_model(self) 함수에서 마지막 분류기(classifier)를 분류하고자 하는 데이터셋의 카테고리 수로 초기화를 합니다.
[Train_model 함수 설명]
위의 클래스를 통해 원하는 데이터셋에 대해 분류하기 위한 모델생성을 마쳤다면 이제 train_model 함수를 통해 학습 및 평가를 을 진행합니다.
def train_model(model, property, hyper_parameter, dataloaders, dataset_sizes, class_length, classes, class_index):
# TODO: 2. 손실함수와 Optimizer 정의 & Train set 을 사용하여 신경망을 학습하기 & Test set(=validation set)을 사용하여 검사
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
'''
2. 손실함수와 Optimizer 정의
Learning Rate Scheduler를 사용하면 좀 더 효율적으로 Global Minimam에 수렴할 수 있다.
예를 들면 특정 Epoch마다 Learning Rate를 다르게 해서 좀 더 효율 적으로 Global minima
에 수렴할 수 있도록 도와준다.
lr, momentum, step_size, gamma는 parametar로 받을 수 있도록 조정
'''
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), hyper_parameter["learning_rate"], hyper_parameter["momentum"])
scheduler = lr_scheduler.StepLR(optimizer, hyper_parameter["step_size"], hyper_parameter["gamma"])
# 2. Train set 을 사용하여 신경망을 학습하기 & Test set(=validation set)을 사용하여 검사
since = time.time() # 시작 시간을 기록(총 소요 시간 계산을 위해)
# fc를 초기화한 model의 parameter를 저장
best_model_wts = deepcopy(model.state_dict())
best_acc = 0.0
num_epochs = hyper_parameter["epoch"]
# 지정한 epoch을 돌며 training
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1)) # epoch를 카운트
print('-' * 10)
# 각 에폭(epoch)은 학습 단계와 검증 단계를 갖습니다.
for phase in ['train', 'val']: # train mode와 validation mode순으로 진행
if phase == 'train':
model.train() # 모델을 train 모드로 설정
else:
model.eval() # 모델을 eval(=val) 모드로 설정
running_loss = 0.0
running_corrects = 0
# 데이터를 반복
step = hyper_parameter["user_step"]
total_step = hyper_parameter["user_step"]
best_step_acc = 0.7
label_array = [0 for i in range(class_length)] # 정답값을 담는 array
total_array = [[0 for col in range(class_length)] for row in range(class_length)] # 정답(labels)과 preds(예측값) 비교 후 담는다.
for index, data in (enumerate(tqdm(dataloaders[phase]))):
inputs = data[0].to(device)
labels = data[1].to(device)
# 매개변수 Gradiant를 0으로 초기화
optimizer.zero_grad()
# 순전파(foward)
# 학습 시(train)에만 연산 기록을 추적
# CustomModel클래스에서 모델생성시 결정됨
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# 학습 단계인 경우 역전파 + 최적화
if phase == 'train':
loss.backward()
optimizer.step()
# csv로 통계내기 위한 코드 : label에 해당하는 category에 카운팅
if phase == 'val':
for i in range(len(labels)):
total_array[int(labels[i])][int(preds[i])] += 1 # 계속 누적이 될 것
label_array[int(labels[i])] += 1 # 계속 누적이 될 것
# 정해진 step마다 acc를 비교하여 높은 step은 저장을 한다.
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if index > 0 and index % step == 0 and phase == 'val':
step_acc = running_corrects.double() / (hyper_parameter['batch_size'] * total_step)
total_step = total_step + step # step을 일단 10으로 지정 --> 나중에 step이라는 hyper parameter표시
if step_acc > best_step_acc:
best_step_acc = step_acc
best_step_wts = deepcopy(model.state_dict())
# 정해진 step마다 정한 기준 정확도보다 높다면 저장을 한다.
weight_save_path = f'{property["save_step_weight_file"]}[{hyper_parameter["root"]}]{str(epoch)}epoch_{str(total_step)}step.pth'
torch.save(best_step_wts, weight_save_path)
#높은 acc를 가졌을때 저장을 해야하며 저장을 할때마다 "맞춘갯수 / 레이블갯수"로 해야한다.
#csv로 통계내기 위한 코드 : 정해진 step마다 잘 나온 weight의 통계를 csv로 저장한다.
tmp_array = total_array[:] # '/'를 붙여주기 위해 임시로 생성하는 돌때마다 초기화 되도 상관x
df = pd.DataFrame(tmp_array)
df.rename(index=class_index, inplace=True)
df.to_csv(
f'{property["save_csv_heat_file"]}[{hyper_parameter["root"]}]{str(epoch)}epoch_{str(total_step)}step_statistic.csv',
header=classes)
# 통계 엑셀 -> heatmap
showAttention(classes, property, hyper_parameter['root'], epoch, total_step, label_array) # 나중에 안으로 넣어야함
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
# 모델을 깊은 복사(deep copy)함
# val을 수행하고
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = deepcopy(model.state_dict())
b_acc = str(best_acc.item())[2:4]
# print(best_acc.item())
tmp_array = total_array[:] # '/'를 붙여주기 위해 임시로 생성하는 돌때마다 초기화 되도 상관x
# 에폭마다 csv, heatmap을 생성, 정확도가 더 높은 epoch일때 생성한다.
df = pd.DataFrame(tmp_array)
df.rename(index=class_index, inplace=True)
df.to_csv(
f'{property["save_csv_heat_file"]}[{hyper_parameter["root"]}]{b_acc}%_{str(epoch)}epoch_statistic.csv',
header=classes)
showAttention(classes, property, hyper_parameter['root'], epoch, total_step,
label_array, b_acc) # 나중에 안으로 넣어야함
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# 가장 나은 모델 가중치를 불러옴
model.load_state_dict(best_model_wts)
# 가장 나은 모델 가중치를 저장
weight_save_path = property["model_weight_file"]
torch.save(best_model_wts, weight_save_path)
return model코드가 무척 길어졌는데... 중간에 csv파일을 통해 시각화하는 부분까지 추가가 되서 그런지 기존 코드보다 많이 길어졌다. (연습이 많이 필요할 것 같습니다ㅠ)
- 전이학습 실습편을 포스팅하면서 학습과 평가를 동시에 하는 구조를 그대로 가져다 썻지만 내가 설정한 step마다 이전의 step의 정확도보다 높으면 csv를 생성하여 통계를 저장하는 부분과 showAttention() 함수를 통해 heatmap을 생성하는 부분이 추가가 되었습니다. 주의할 점은 통계csv파일과 heatmap은 val, test data일 경우에만 진행하도록 구현하였고 내가 지정한 step마다 그리고 최고의 정확도를 보이는 에폭에 대해서만 생성이 되도록 했습니다.
- csv, heatmap을 통해 평가지표를 나타냄과 동시에 가중치 또한 저장하였습니다.
이제 학습을 시작해보겠습니다!! 그전에 데이터셋은 11개의 카테고리가 존재합니다.
train_data.zip
drive.google.com
Epoch 7/11
----------
100%|███████████████████████████████████████████████████████████████| 239/239 [00:46<00:00, 5.11it/s]
train Loss: 0.2030 Acc: 0.9601
100%|█████████████████████████████████████████████████████████████████| 53/53 [00:07<00:00, 7.09it/s]
val Loss: 0.1097 Acc: 0.9788
Epoch 8/11
----------
100%|███████████████████████████████████████████████████████████████| 239/239 [00:47<00:00, 5.05it/s]
train Loss: 0.1969 Acc: 0.9625
100%|█████████████████████████████████████████████████████████████████| 53/53 [00:07<00:00, 7.12it/s]
val Loss: 0.1049 Acc: 0.9858
Epoch 9/11
----------
100%|███████████████████████████████████████████████████████████████| 239/239 [00:46<00:00, 5.11it/s]
train Loss: 0.1899 Acc: 0.9609
100%|█████████████████████████████████████████████████████████████████| 53/53 [00:07<00:00, 7.12it/s]
val Loss: 0.1076 Acc: 0.9800
Epoch 10/11
----------
100%|███████████████████████████████████████████████████████████████| 239/239 [00:46<00:00, 5.10it/s]
train Loss: 0.1872 Acc: 0.9654
100%|█████████████████████████████████████████████████████████████████| 53/53 [00:07<00:00, 7.11it/s]
val Loss: 0.1085 Acc: 0.9835
Epoch 11/11
----------
100%|███████████████████████████████████████████████████████████████| 239/239 [00:46<00:00, 5.10it/s]
train Loss: 0.1913 Acc: 0.9604
100%|█████████████████████████████████████████████████████████████████| 53/53 [00:07<00:00, 7.19it/s]
val Loss: 0.1055 Acc: 0.9776Training complete in 10m 53s
Best val Acc: 0.985849
총 11epoch을 돌렸으며 정확도는 무려 98%가 나왔습니다.
[showAttention() 함수 설명]
코드 중간에 step 또는 epoch 마다 높은 정확도를 보일 때 heatmap을 만들어 통계를 시각화하는 showAttention() 함수가 보입니다.
def showAttention(classes, property, root, epoch, step, label_array, acc=None):
# TODO : 통계를 히트맵 시각화하기 위한 메소드
if acc is not None: # epoch인경우
csv_test = pd.read_csv(f'{property["save_csv_heat_file"]}[{root}]{acc}%_{str(epoch)}epoch_statistic.csv')
else:#step인 경우
csv_test = pd.read_csv(f'{property["save_csv_heat_file"]}[{root}]{str(epoch)}epoch_{str(step)}step_statistic.csv')
# '|' 표시를 추가해주고 다시 덮어쓴다.
final_csv = csv_test[:]
final_csv = final_csv.to_numpy()
final_csv = np.delete(final_csv, 0, axis=1)
for i in range(len(final_csv)):
for j in range(len(final_csv[i])):
final_csv[i][j] = str(final_csv[i][j]) + '|' + str(label_array[i])
df = pd.DataFrame(final_csv)
df.rename(index=class_index, inplace=True)
if acc is not None:
df.to_csv(
f'{property["save_csv_heat_file"]}[{root}]{acc}%_{str(epoch)}epoch_statistic.csv',
header=classes)
else:
df.to_csv(
f'{property["save_csv_heat_file"]}[{root}]{str(epoch)}epoch_{str(step)}step_statistic.csv',
header=classes)
csv_test = csv_test.to_numpy()
csv_test = np.delete(csv_test, 0, axis=1)
num_arr = [[0 for col in range(len(classes))] for row in range(len(classes))]
num_arr = np.array(num_arr)
for i in range(len(csv_test)):
for j in range(len(csv_test[i])):
try:
num_arr[i][j] = (csv_test[i][j] / label_array[i]) * 100
except ZeroDivisionError:
num_arr[i][j] = 0
csv_test = num_arr.astype(np.int64)
fig, ax = plt.subplots()
im = ax.imshow(csv_test)
color_bar = ax.figure.colorbar(im, ax=ax)
color_bar.ax.set_ylabel("accuracy", rotation=-90, va="bottom")
# We want to show all ticks...
ax.set_xticks(np.arange(len(classes)))
ax.set_yticks(np.arange(len(classes)))
# ... and label them with the respective list entries
ax.set_xticklabels(classes)
ax.set_yticklabels(classes)
# Rotate the tick labels and set their alignment.
plt.setp(ax.get_xticklabels(), rotation=45, ha="right",
rotation_mode="anchor")
# Loop over dataset dimensions and create text annotations.
for i in range(len(classes)):
for j in range(len(classes)):
text = ax.text(j, i, csv_test[i, j],
ha="center", va="center", color="w")
ax.set_title("similar image heatmap")
fig.tight_layout()
# plt.show()
if acc is not None:
fig.savefig(f'{property["save_csv_heat_file"]}[{root}]{acc}%_{str(epoch)}epoch_heatmap.jpg')
else:
fig.savefig(f'{property["save_csv_heat_file"]}[{root}]{str(epoch)}epoch_{str(step)}step_heatmap.jpg')
함수 도입 부분에 if문을 써준건 step.csv, epoch.csv를 구분해주기 위함입니다. 더 간단히 효율적으로 코드를 작성할 수 있을텐데 많이 아쉬웠던 부분이기도 합니다..
어쨋든간에 csv파일과 heatmap을 보면 이렇습니다.
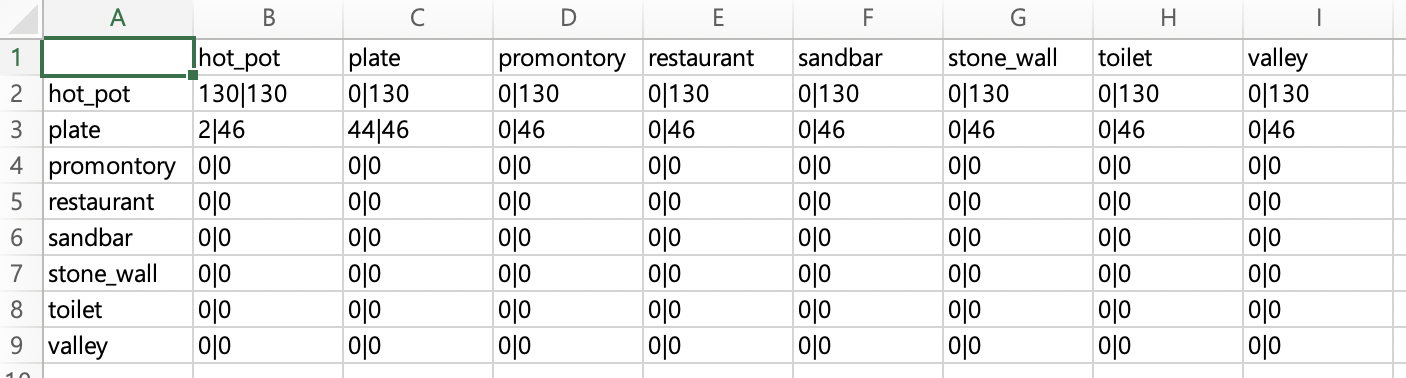
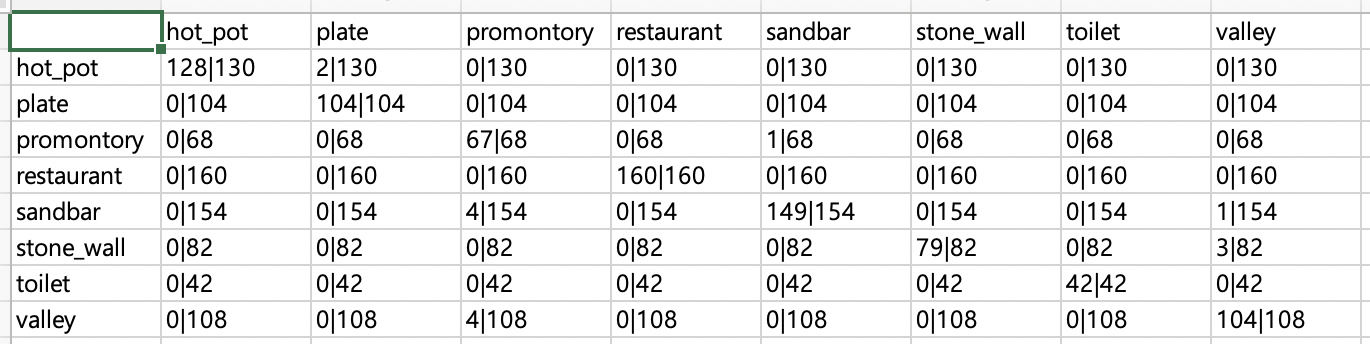
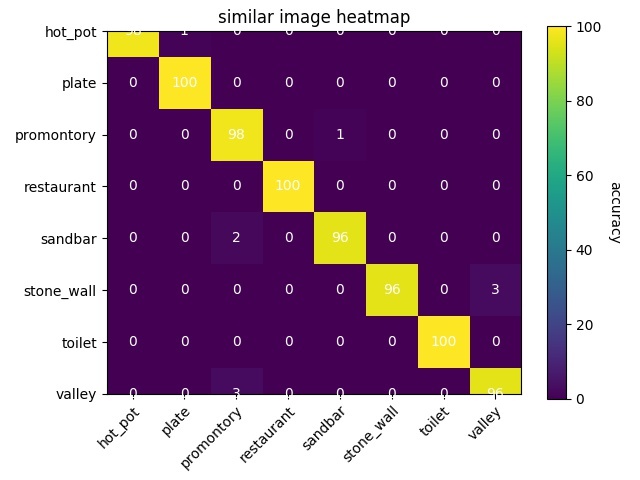
이렇게 통계를 csv, heatmap으로 시각화함으로써 한눈에 더 이해하기 쉬워지는 것 같습니다. 그리고 step마다 도중에 평가하고 가중치를 저장하는 부분이 이해가 안되서 멘토님께 물어보니 학습 도중에 평가가 잘되고 있는지와 중간에 학습이 끊겨 다시 시작하기를 원할때를 위해서라고 합니다. 아직도 감이 잡히지 않지만 keras의 callback을 의미하는 것 같습니다.
이렇게 '유사이미지분류' trainer.py 구현 과제를 마무리하였습니다.
아직 보완해야할 점도 많지만 제가 관심있는 분야에 대해 여러방면으로 섬세하게 배울 수 있어 좋았습니다.(특히 협업)
'인턴쉽 > 동계백마인턴쉽(2021)' 카테고리의 다른 글
| [5주차] '유사 이미지 분류' Trainer코드 제작 (0) | 2021.02.08 |
|---|---|
| [4주차] 전이학습(Transfer Learning) <실습 정리편> (0) | 2021.02.08 |
| [4주차] 전이학습(Transfer Learning) <이론 정리편> (0) | 2021.02.08 |
| [2~3주차] DenseNet <이론 정리편> (0) | 2021.02.08 |
| [1주차] 환경세팅하기 (Anaconda + PyTorch) (1) | 2021.02.08 |



